Application performance can make or break user experience. When milliseconds matter, traditional database queries often become bottlenecks that slow down even the most well-architected applications. This is where distributed caching systems shine, and Redis has emerged as one of the most popular solutions for solving performance challenges at scale. Understanding the principles behind designing Redis distributed caching systems is essential for any developer or architect building high-performance applications that serve millions of users worldwide.
The Core Architecture Principles
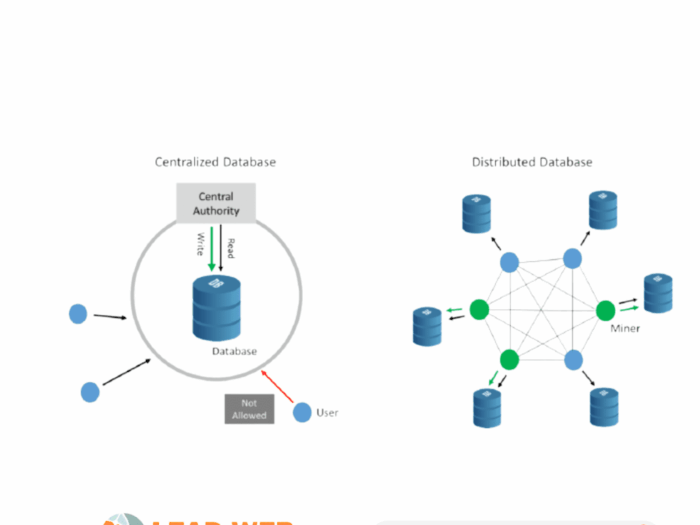
When designing Redis distributed caching systems, the foundation lies in understanding how data should be stored, accessed, and distributed across multiple nodes. Unlike traditional databases that prioritize durability and consistency above all else, caching systems optimize for speed and availability. The architecture must support in-memory data structures that allow for microsecond-level access times while maintaining the flexibility to handle various data types including strings, hashes, lists, sets, and sorted sets.
The key to designing a Redis distributed caching system effectively is choosing the right data structure for each use case. For example, using sorted sets for leaderboards, hashes for user session data, and simple key-value pairs for frequently accessed database query results. Each structure offers different performance characteristics and use cases that influence overall system design.
Implementing Data Partitioning Strategies
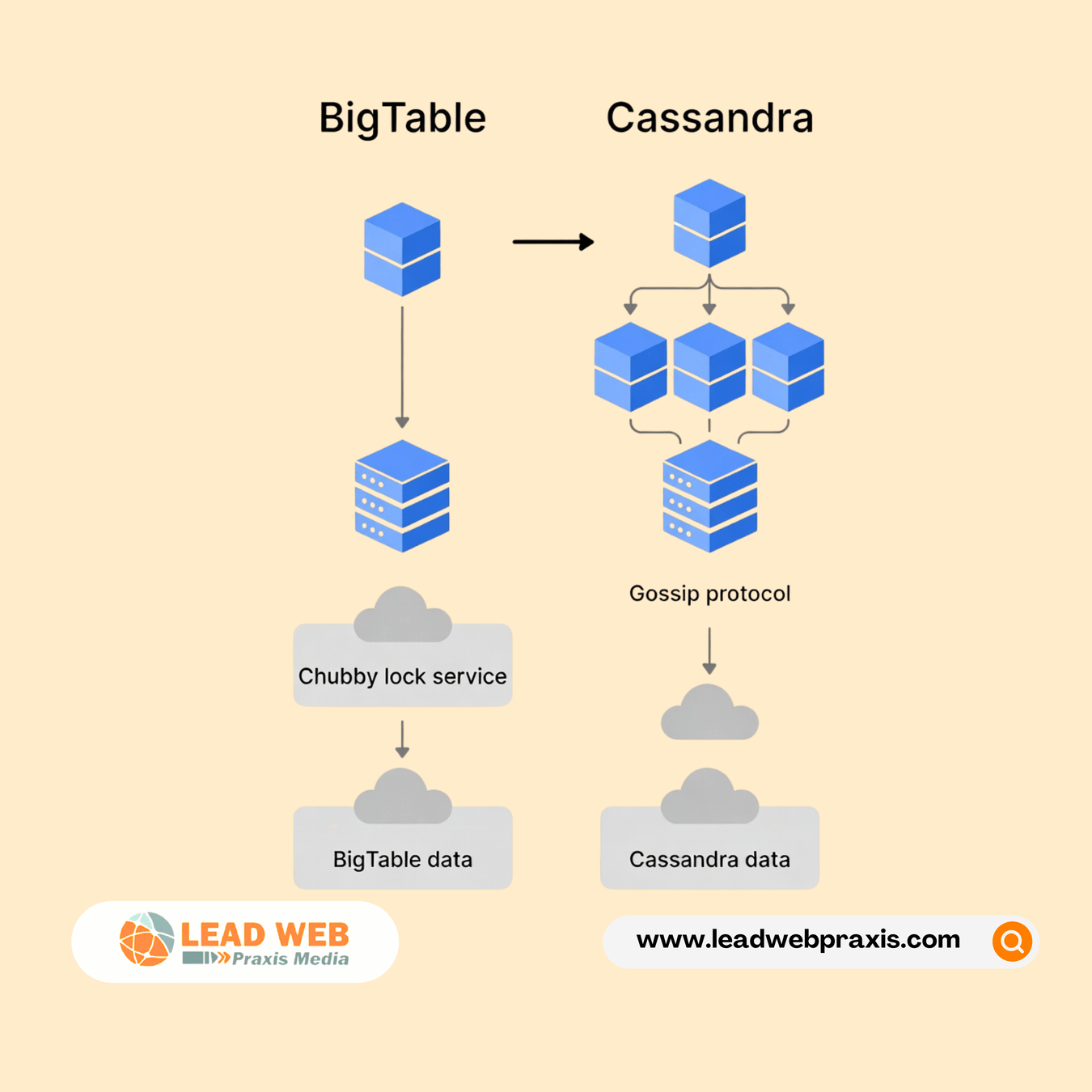
One critical aspect of designing Redis distributed caching systems involves data partitioning, commonly known as sharding. As your data grows beyond what a single server can handle, you need a strategy to distribute keys across multiple Redis instances. Consistent hashing has become the industry standard approach because it minimizes data movement when nodes are added or removed from the cluster.
The partitioning strategy you choose impacts everything from performance to operational complexity. Hash slot-based partitioning, which Redis Cluster uses, divides the key space into 16,384 slots and assigns ranges of these slots to different nodes. This approach makes designing a Redis distributed caching system more predictable and manageable at scale.
Ensuring High Availability and Replication
High availability is non-negotiable when designing Redis distributed caching systems for production environments. The system must continue serving requests even when individual nodes fail. Redis achieves this through master-replica replication, where each master node has one or more replica nodes that maintain synchronized copies of the data.
The replication mechanism works asynchronously by default, meaning the master doesn’t wait for replicas to confirm writes before responding to clients. This design choice prioritizes performance but introduces a small window where data could be lost if a master fails before replicas sync. When designing Redis distributed caching systems, you must balance these tradeoffs between consistency, availability, and performance based on your specific requirements.
Sentinel processes monitor the health of master and replica nodes, automatically promoting replicas to master status when failures occur. This automatic failover capability is essential for designing Redis distributed caching systems that meet demanding uptime requirements.
Handling Client-Side Logic and Connection Pooling
The client layer plays a crucial role when designing Redis distributed caching systems. Smart clients need to understand the cluster topology, route requests to the correct nodes, and handle redirections when keys have moved between nodes. Connection pooling becomes critical at scale because establishing new connections introduces latency that undermines the speed advantages of caching.
Modern Redis clients implement sophisticated connection management, including automatic reconnection logic, request pipelining to batch commands, and support for reading from replicas to distribute load. When designing a Redis distributed caching system, selecting or building clients with these capabilities ensures your application can fully leverage the cache’s performance potential.
Managing Cache Invalidation and Eviction Policies
Cache invalidation remains one of the hardest problems in computer science, and designing Redis distributed caching systems requires careful consideration of when and how to remove stale data. Redis provides several eviction policies including LRU (Least Recently Used), LFU (Least Frequently Used), and TTL-based expiration. Choosing the right policy depends on your access patterns and data characteristics.
For some applications, designing a Redis distributed caching system with write-through or write-behind caching patterns ensures data consistency between cache and database. Others rely on TTL-based expiration where cached entries automatically expire after a configured time period. The key is understanding your data’s lifecycle and access patterns to implement appropriate invalidation strategies.
Monitoring and Observability
You can’t optimize what you can’t measure. When designing Redis distributed caching systems, comprehensive monitoring becomes essential for understanding performance, identifying bottlenecks, and planning capacity. Key metrics include hit rate, memory usage, eviction count, network throughput, and command latency percentiles.
Modern monitoring solutions provide real-time visibility into cluster health, allowing teams to detect and respond to issues before they impact users. Designing a Redis distributed caching system with observability built in from the start makes troubleshooting easier and helps teams make data-driven decisions about scaling and optimization.
AI Considerations for Cache Optimization
How might artificial intelligence and machine learning change how we approach designing Redis distributed caching systems in the future? Predictive caching, where AI models analyze access patterns to pre-load data before it’s requested, could dramatically improve hit rates. Machine learning could also optimize eviction policies dynamically based on real-time workload characteristics rather than relying on static configurations.
Conclusion
Successfully designing Redis distributed caching systems requires deep understanding of distributed systems principles, careful attention to operational details, and continuous optimization based on real-world performance data. From data partitioning and replication to client-side logic and monitoring, each component must work together harmoniously to deliver the microsecond latencies that modern applications demand.
If you’re looking to implement or optimize distributed caching for your applications, the experts at Lead Web Praxis can help. With extensive experience designing Redis distributed caching systems for organizations of all sizes, Lead Web Praxis offers consulting, implementation, and managed services to ensure your caching infrastructure performs reliably at scale. Reach out to Lead Web Praxis today to discuss how distributed caching can transform your application’s performance and user experience.